|
Chapitre XI : Système d'information
(extrait de Michel
Volle, e-conomie, Economica 2000)
1. Priorité des usages
Le rôle du système d'information dans les entreprises est en
train de changer. La décentralisation de puissance et de mémoire induite par la
dispersion des micro-ordinateurs les oriente vers de nouvelles architectures et vers un
partage différent des responsabilités entre utilisateurs du système d'information et
informaticiens. Un ensemble de techniques nouvelles modifie le champ du possible et
introduit un vocabulaire nouveau : client-serveur, orienté objet, Intranet, Extranet,
Datawarehouse, Datamining, Workflow, e-business etc.
La définition usuelle du système d'information ressemblait
naguère à ceci : " Le système d'information est l'ensemble des informations
formalisables circulant dans l'entreprise et caractérisées par des liens de dépendance,
ainsi que des procédures et des moyens nécessaires pour les définir, les rechercher,
les formaliser, les conserver, les distribuer ".
Mais cette définition n'indiquait ni à quoi sert le système
d'information, ni comment il est construit : elle ignorait sa dynamique. Pour
décrire celle-ci, il faut distinguer deux faces du système d'information : l'une
orientée vers les moyens (" système informatique "), l'autre vers
les besoins et usages, auxquels la réflexion sur le système d'information donne
désormais une place croissante.
Les moyens de l'informatique sont la puissance de calcul
(mesurée en MIPS), la mémoire (mesurée en octets), l'" intelligence "
(logiciels), les réseaux (largeur de bande, protocoles), les outils (langages, ateliers
de génie logiciel, passerelles, " middleware " etc.)
L'offre de machines et logiciels foisonne. Elle est très
évolutive et la concurrence est féroce. L'informaticien doit connaître les produits et
les passerelles qui permettent de les faire communiquer. Il faut être du métier pour
interpréter les annonces des fournisseurs et choisir la " solution "
(combinaison de composants matériels et logiciels) la plus convenable en termes de
rapport qualité/prix, d’évolutivité et de pérennité. Le travail de
l’intégrateur, qui n’a d’ailleurs jamais été facile, exige une
compétence professionnelle de plus en plus exigeante.
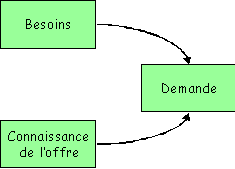
Le client de l'informatique, ou " maître d'ouvrage ",
c'est la personne morale (entreprise, direction) qui réalise des tâches opérationnelles
ou prépare des décisions. L’Informatique est pour ce client un outil. Il exprime
ses besoins en formulant une demande ; mais toute demande résulte de la rencontre d'un
besoin et de la connaissance d'une offre, et même s’il sa spécialité n’est
pas l’informatique le maître d’ouvrage ne peut pas se permettre d’ignorer
les possibilités et contraintes de celle-ci.
Si quelqu'un veut faire construire sa maison, il faut qu'un
architecte l'aide à traduire son besoin en demande pertinente. S'il s'agit d'un système
d'information, l'" architecte " s'appelle " assistant à maître
d'ouvrage ". Seul le client est porteur légitime de son besoin, mais l'expression de
ce besoin nécessite l'aide d'un spécialiste.
2. Processus
Le salarié d'hier était un ouvrier devant ses outils ou sa
machine ; le salarié d'aujourd'hui est un employé devant son micro-ordinateur. Les
entreprises s'organisent autour du système d'information dont le support physique est
réparti sur des ordinateurs communiquant via le réseau. Le travail, devenu immatériel,
est essentiellement une manipulation de concepts et de données, les " produits
" de ce travail (plans, rapports, notices etc.) n'étant que des supports
d’informations. Bien sûr des biens matériels ou des services sont produits en
définitive, mais avec peu de travail physique.
Les NTIC bousculent la définition de la valeur. Celle-ci
réside non dans les produits stockés ou immobilisés, mais dans leur conception où
réside l’essentiel du coût de production. La part du capital fixe dans l'actif de
l'entreprise décroît. Son actif principal est désormais la conjonction entre le stock
des compétences d’une part, son aptitude à en organiser la mise en œuvre
d'autre part. On peut distinguer dans ces compétences celles concernant la gestion
d’un stock (formation et accumulation) et celles concernant la gestion d’un flux
(mise en œuvre dans l'action).
Ce flux, c'est celui des processus, qu’ils soient
opérationnels ou qu’ils contribuent aux décisions. Le bon décideur n'est pas celui
qui s'attache à prendre en toutes circonstances la meilleure décision (ambition
surhumaine), mais celui qui prend soin de mettre en place les processus qui alimentent sa
vigilance en minimisant le risque d'erreur. L'organisation des processus, c'est le réseau
de l'entreprise. L'entreprise qui s'organise pour parcourir efficacement ses processus,
c’est l'" entreprise-réseau " où une organisation transverse
permet aux personnes compétentes de coopérer sans perte de temps. Les processus
s'organisent en " workflows " reliant les activités et expertises.
Les workflows permettent de baliser les circuits, de maîtriser les délais, de diffuser
des alarmes et d’éclairer l'état de la procédure. Certains voient dans le workflow
l'innovation la plus importante dans les systèmes d'information. La hiérarchie participe
à leur conception, délègue la responsabilité opérationnelle de leur mise en
œuvre, et intervient a posteriori pour réguler leur utilisation.
Architecture " client service "
Nous citons ci-dessous Evelyne Chartier :
Aujourd'hui 70 % des Directions Informatiques sont orientées "
techniques et coûts ", en 2000, 70 % seront orientées " clients et business
".
En 2000, 85% des applications existantes auront été touchées par une
évolution liée à la technologie ou à des évolutions architecturales. 70 % des
applications seront développées hors des directions informatiques
Le travail en groupe (workgroup) sera largement répandu.
L’Informatique d'amélioration de la productivité ne disparaîtra pas, mais elle
sera encapsulée dans une informatique de valeur ajoutée.
L'architecture du système d'information est le modèle des métiers de
l'entreprise. Il ne s'agit plus seulement de structurer l'information en vue d'un
traitement informatique, mais d'établir une cartographie de la réalité de l'entreprise.
Analyser avec lucidité la vision du système d'information tel qu'il est perçu par le
client, s'intéresser aux services qu'il pourrait en attendre, ces préoccupations vont
devenir vitales. Tous les moyens technologiques doivent être utilisés pour valoriser au
maximum les instants de contact avec le client et créer de l'activité commerciale. On
passe de l'architecture client-serveur vue par les informaticiens à l'architecture
client-service vue par le business.
On va assister à l'émergence d'un marché de composants logiciels sur
étagère (catalogues de produits accessibles et commercialisés via Internet). Au lieu
des applications fractionnées de l'informatique de production lourde, le système
d'information sera un maillage de serveurs internes et externes et de services. Chaque
utilisateur aura la vue qui correspond à son besoin du moment, en fonction de son
activité.
Une organisation entièrement fondée sur l'utilisation des nouvelles
technologies va émerger avant cinq ans : c'est le " busyware ", qui recouvre un
savant dosage de données, transactions, documents, workgroup et workflow.
3. Culture des usages
Les NTIC nous apportent beaucoup, mais leur bon usage réclame
une maturité, un savoir vivre, aux antipodes de la fébrilité de certains néophytes.
Elles ont des effets pervers qu’il faut traiter avec une précision cliniques sous
peine de donner raison à ceux qui sont " contre les NTIC " parce
qu’elles représenteraient " le mal ".
Ce n’est certes pas la première fois que l’humanité
se voit dotée d’outils dont la nouveauté déconcerte : pensons aux
bouleversements qu’ont suscités l’écriture, puis le livre imprimé, et dont
l’histoire a gardé les traces.
Voici donc une liste, certainement non exhaustive, des effets
pervers que les utilisateurs doivent apprendre à maîtriser :
- la mémoire de l'ordinateur, exhaustive, ne comporte pas le mécanisme d'oubli
sélectif qui suscite le travail de synthèse et exerce l’intelligence. Tout garder
en mémoire, c'est ne rien comprendre ;
- si les traitements de texte, tableurs etc. aident à traiter vite des problèmes
urgents, ils encouragent aussi un activisme qui s'oppose à la maturation de la pensée et
à la sélection des priorités ;
- la qualité des présentations risque de masquer la pauvreté du contenu :
l’abondance des tableaux de nombres et des graphiques n’apporte rien si les
données sont mal définies ; la beauté des transparents PowerPoint fascine, mais
risque de faire oublier le vide de certains exposés et apporte donc un alibi commode à
la superficialité ;
- la messagerie et surtout les forums exigent des utilisateurs un effort de
politesse (Ia " Netiquette "). Ils doivent prendre garde au ton qu’ils
emploient : si un message est écrit trop vite, ils sera jugé agressif et les
relations entre collègues en pâtiront ;
- la télévision, puis le " surf " sur le Web, nous ont trop habitués
au " zapping " : le parcours rapide des ressources documentaires interdit
l'accès à une pensée structurée et déductive, au bénéfice d'images-choc qui
réveillent l'attention. Il en résulte un handicap pour la maturation et la communication
d'une réflexion.
La culture des usages doit donc accompagner la mise en
œuvre de ces outils. On retrouve ici les préceptes classiques : il faut prendre le
temps de réfléchir, trier et élaguer l'information, prendre du recul pour maîtriser
son activité, construire posément synthèses et démarches. Les règles dégagées par
les humanistes de la Renaissance gardent leur fraîcheur.
Trop souvent ces règles de simple bon sens sont ignorées.
L'utilisation des NTIC attire rarement l'attention des responsables ; elle est laissée à
l'initiative d'équipes qui se livrent, dans la confusion, à d'épuisantes luttes pour
des miettes de pouvoir. Les entreprises ne tirent d’ailleurs pas encore les
conséquences du fait que le micro-ordinateur communiquant est devenu le poste de travail
de chacun. Elles confient les tâches d'organisation à des cabinets qui leur vendent des
méthodologies préfabriquées, et la bureautique à des techniciens mal payés. Les
directions informatiques ont d'ailleurs la nostalgie de l'époque où de gros systèmes
irriguaient des terminaux " bêtes " et où il était facile d'imposer
leur langage à l'entreprise. Enfin, la bureautique reste marquée par un esprit de
bricolage incompatible avec toute ambition en matière de système d'information.
Il en résulte que la mémoire de l'entreprise est négligée :
pas de gestion de la documentation ni des archives, donc pas d'accumulation de
l'expérience technique ou commerciale ; les nouveaux arrivants doivent passer par un long
apprentissage, pour ne pas dire un bizutage. La documentation d'une équipe n'est pas
utilisable par une autre, et sur chaque site on ignore les produits fabriqués ailleurs :
il est difficile de faire travailler ensemble des entités distantes. Le partage des
rôles entre partenaires d'un consortium fait l'objet de négociations répétées parce
que le texte du contrat est difficilement accessible. Les personnes compétentes ne sont
pas consultées lors de la préparation des décisions. Le dossier va d'un bureau à
l'autre, s'attarde dans une pile. Les délais sont aléatoires. Il faut une longue
recherche pour savoir où en est une affaire et la débloquer.
On nous dira " l’Intranet va régler tout
cela ". Sans doute il en donne les moyens techniques ; mais il ne fournit
pas la volonté politique nécessaire pour modifier les valeurs qui adhèrent aux
comportements ci-dessus. Nous examinerons dans le chapitre XII la question des blocages,
que l’on ne doit pas séparer de l’examen des possibilités.
Ces errements n'ont d’ailleurs rien de nouveau. Regardons
le domaine déjà ancien des télécommunications : les télécopieurs étaient, au
début des années 90, réservés au secrétariat du président ou du DG ; beaucoup
d’entreprises négligent les économies qu'elles pourraient faire en observant le
trafic et en retenant des PABX compatibles ; les câblages sont souvent
inextricables, non documentés, redondants ; les messageries sont souvent inutilisées
parce qu’elles débordent de messages parasitaires ; les expérimentations sont
inadéquates ; les compléments du service téléphonique ignorés, l’accueil
téléphonique est rébarbatif, etc. Nous exagérons ? faisons ensemble un test en
deux questions, et vous tirerez vous-même les leçons de vos réponses :
- savez-vous comment transférer un appel à partir de votre poste
téléphonique ?
- l’accueil de votre standard téléphonique est-il efficace ?
Si les NTIC relèvent de techniques complexes, et si leur
conception a nécessité une réflexion d'excellent niveau, leur mise en œuvre
réclame de la modestie, du bon sens, une énergie persévérante, et beaucoup de courage
- car il faut oser prendre quelques risques personnels pour les faire avancer.
4. Transition vers les processus
Les systèmes d'information s'organisent désormais autour des
processus de l'entreprise. Pour illustrer ce changement, nous décrirons deux "
modèles " que nous nommerons M1 et M2.
Dans M1, qui représente la situation la plus traditionnelle, le
système d'information se construit autour des applications informatiques.
Dans M2, le système d’information se construit autour des
processus des métiers.
Le rôle de l'informatique change lors du passage de M1 à M2.
Modèle M1 : les applications
Une application, c'est une suite de traitements appliquée sur
des données initiales (" input ") pour fournir un résultat (" output
"). Les données initiales sont soit introduites dans l'application par saisie ou
comptage automatique, soit issues d'autres applications. Les traitements sont soit des
additions permettant de mesurer des agrégats à partir de données détaillées, soit des
calculs plus spécifiques.
Le fondement d'une application, tel que le définit Merise,
réside dans deux modèles : le modèle conceptuel de données comprend les définitions
sémantique et technique des données ; le modèle applicatif décrit les traitements.
Nous allons décrire deux scénarios de mise en œuvre du
modèle M1: le premier, " rose ", montre comment les choses devraient se
passer pour que tout marche bien. Le second, " gris ", montre comment elles se
passent le plus souvent.
Scénario " rose "
L'application limite la saisie au strict nécessaire, automatise
les traitements, et affiche sur l'écran (ou imprime sur papier) les résultats dont
l'utilisateur a besoin. La récupération des données issues d'autres applications est
automatique, seules les données nouvelles faisant l'objet d'une saisie manuelle.
L'informaticien, qui reçoit les demandes de divers
utilisateurs, construit son architecture de données et de traitements sous une double
contrainte de qualité et d'économie. Il répartit ainsi les ressources (mémoire,
puissance de calcul, débit des liaisons télécoms) et définit des applications
intermédiaires. La cohérence des applications est alors réalisée au sein du système
informatique, cœur du système d'information.
La qualité de l'écriture des programmes garantit qu'il sera
facile de les faire évoluer lorsque les besoins changeront.
Scénario " gris "
L'urgence, l'insouciance, l'optimisme, le cloisonnement de
l'organisation poussent à concevoir et développer les applications au coup par coup,
selon l'arrivée des demandes, sans que la relation avec les autres applications soit
maîtrisée ; des données de référence sont redéfinies pour chaque application; les
plates-formes techniques (machines, système d'exploitation, langage) sont choisies en
fonction des ressources disponibles lors du développement ; les interfaces présentées
à l'utilisateur sont hétéroclites (touches de fonction et codages spécifiques à
chaque application). La " gestion de configuration " (documentation des versions
successives d'une application) est laissée à la bonne volonté des chefs de ligne de
produit et certains la négligent. Beaucoup d'incidents restent inexpliqués.
L'entreprise, pour sa part, considère l'informatique comme un
centre de coût, non comme un centre d'investissement au service des métiers. La pression
budgétaire est exercée de façon mécanique et aveugle par une " enveloppe
informatique ". Une méfiance se crée entre les informaticiens et l'entreprise.
Les engagements sur les coûts et délais ne sont jamais tenus. L'informatique se divise
en petites baronnies jalouses chacune de son indépendance.
Modèle M2 : les processus
Le terme de " processus " désigne l'enchaînement des
tâches réalisées pour remplir une fonction de l'entreprise, pour produire une valeur
ajoutée. Ces tâches sont soit mentales (perception, jugement, décision) soit physiques
(imprimer un billet, le livrer à un client, réaliser une opération de maintenance), les
tâches mentales préparant les tâches physiques.
Le système d'information vise à assister l'utilisateur dans la
réalisation des tâches mentales liées aux processus.
Formaliser un processus conduit à l'équiper d'un "
workflow ", c'est-à-dire d'une documentation explicite des tâches et de leurs
relations :
- préciser les interfaces nécessaires à chaque activité (on regroupe sur le
même écran les plages de consultation et de saisie nécessaires à une activité, ce qui
évite à l'utilisateur la connexion à d'autres applications ainsi que la navigation dans
des codes et touches de fonction diverses),
- programmer les tables d'adressage permettant de router automatiquement les
messages à l'issue d'une tâche (lorsque l'utilisateur tape sur la touche " valider
" qui marque la fin de son travail, il n'a pas à chercher à qui envoyer le
résultat).
Le délai de réalisation d'une tâche est surveillé par un
" timer " qui prévient l'utilisateur en cas de dépassement, ou qui reroute le
message vers un autre utilisateur.
Exemple d’interface utilisateur
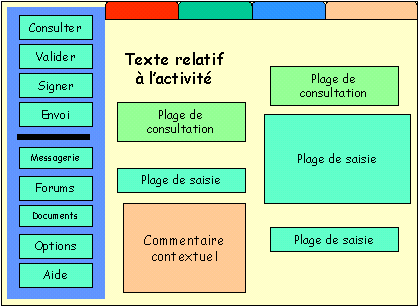
Modéliser un processus, c'est décrire la succession des
tâches qui concourent à une production de valeur ajoutée : ce que fait chaque acteur,
les données qu'il manipule, les traitements qu'il ordonne, les délais dans lesquels son
travail doit être exécuté, le routage de ses messages vers d’autres acteurs, les
compteurs qui permettent au responsable du processus de contrôler la qualité.
L’une des utilisations pratiques réside dans le workflow
commercial, dont on peut représenter les étapes de la façon suivante :
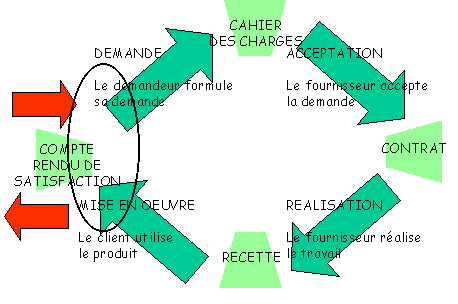
La réalisation physique des tâches est décrite dans le
modèle du processus, puisqu'il la documente, mais elle nécessite une action qui ne peut
être réalisée que par un être humain et échappe donc à l'ordinateur, même si
celui-ci aide sa préparation. Le workflow relève donc de l'" assisté par
ordinateur ", non de l'automatisation ; il aide l'utilisateur sans se substituer à
lui, tout en automatisant des tâches que l'on faisait auparavant à la main.
Représentation du processus
Un processus se décrit sous la forme d'un graphe. Les
nœuds représentent les tâches élémentaires " activités "), les
arcs représentent les messages émis à la fin d'une tâche pour lancer la (ou les)
tâche(s) suivante(s).
Il est commode de donner à ce graphe la forme circulaire qui
montre bien que le processus est déclenché par un fait extérieur et physique
(réception d'une commande, d'une lettre de réclamation, franchissement du délai de
maintenance d'un équipement) auquel le processus répond par une action physique sur
l'extérieur (livraison, lettre, opération de maintenance). Il convient de s'assurer que
cette réponse a lieu dans un délai et sous la forme convenable : c'est le contrôle
du bouclage du processus.

Il faut souvent introduire d'autres compteurs (volume, délai,
valeur etc.). En effet, la formalisation du processus suscite une organisation impliquant
une délégation de responsabilité aux personnes qui réalisent les tâches.
L'intervention de l'encadrement ne se fonde plus sur l'approbation des actes un par un,
mais sur un contrôle statistique a posteriori et sur la diffusion de consignes nouvelles
si des dysfonctionnements apparaissent ou si l'on veut faire évoluer le processus.
La réalisation d'un processus suppose souvent des
sous-processus fournissant chacun des " livrables " intermédiaires (exemple :
expertise fournie lors de l'instruction d'une demande d'autorisation d'investissement ou
d’une demande de crédit).
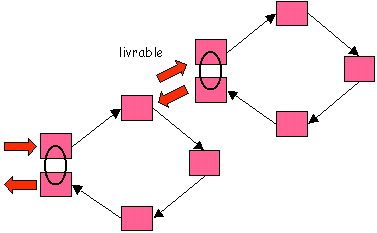
Le processus a une existence de facto, avant toute
description. Mais un processus qui n'a pas été pensé présente très souvent des
défauts. Par exemple il ne boucle pas : la succession des tâches se poursuit sans que
l'on vérifie s'il a bien été répondu à chaque événement extérieur, et le risque
existe que le processus " se perde dans les sables " (c'est le cas lorsqu'une
lettre de client passe de mains en mains sans que personne ne contrôle le délai de
réponse : on finit par renoncer à répondre lorsque le délai décent a été
dépassé).

Organisation transverse
Certaines des fonctions de la hiérarchie intermédiaire, celles
qui se résument à la transmission des consignes vers le bas et des rapports vers le
haut, sont remplacées par le workflow, ses compteurs et l'édition semi automatique de
comptes rendus. Le nombre des niveaux hiérarchiques est donc réduit, la communication
entre " base " et " sommet " est plus facile. Par ailleurs, l'approche
par les processus est souvent " qualifiante ". La transparence, la
diffusion de l'information suppriment l'opacité des procédures, la rétention de
l'information, les mille abus que ces pratiques permettent.
Processus et objets
Pour décrire une interface homme-machine, il suffit d'indiquer
les données que l’utilisateur consulte, celles qu'il saisit, les traitements qu'il
lance, ainsi que l'ordre (éventuellement souple) dans lequel il réalise ces opérations.
Chaque utilisateur va consulter ou saisir quelques données, déclencher un nombre limité
de traitements : ceci conduit très naturellement vers la programmation orientée
objet : un objet est un petit programme qui rassemble les données et les traitements
propres à un des êtres du monde réel, ou à des êtres intermédiaires comme des
dossiers, rapports, calculs etc. sur lequel l’utilisateur entend agir.
Le langage UML, qui fédère les langages de modélisation en
matière d'approche objet, fournit les documents nécessaires à la description des
activités (" use cases " selon le vocabulaire de Jacobson), les classes ("
diagrammes de classes ") et la succession des opérations (" diagrammes de
séquences "). On construit ainsi le " modèle complet " qui, établi
par un maître d'ouvrage et communiqué au maître d'œuvre informatique, indique à
ce dernier ce qui doit apparaître sur les écrans des utilisateurs, les actions que
ceux-ci vont réaliser, ainsi que les compteurs utilisés à des fins de contrôle.
Le modèle complet des processus est plus précis que les
spécifications qui étaient fournies à l'informatique dans le modèle M1. Il indique
sans ambiguïté ce que l'utilisateur veut faire, et aide à découper le développement
en petits modules, les classes, clairement reliées chacune à une finalité pratique
(c'est pour cela que l'on parle d'" objets métier ").
L'analyse des activités fait apparaître que les mêmes classes
sont utiles à plusieurs acteurs ou que l'on peut satisfaire les besoins de plusieurs
acteurs en construisant des classes de forme identique ou analogue (héritage,
polymorphisme). Ces analogies font apparaître des êtres sémantiques nouveaux
concrétisant des concepts inédits. Les langages de développement " orientés objet
" exploitent ces possibilités qui allègent le développement et enrichissent la
conception. Ils réduisent les coûts de maintenance et facilitent l'évolution du
système d'information.
La démarche de modélisation conduit à définir de façon
cohérente les diverses données utilisées par les activités concourant à un même
processus : on peut, en reprenant le diagramme du processus ci-dessus, mettre au
centre de la boucle les données auxquelles se réfèrent les diverses activités et
qu’elles partagent ; le processus fait ainsi une " ronde autour des
données ", celles-ci résidant dans des bases données qui constituent le pivot
du processus.
Passage de M1 à M2
Supposons qu’une entreprise qui répondait au modèle M1 se
décide à passer au modèle M2 en raison des avantages qu’il présente. Le passage
de M1 à M2 suppose un changement pour le système d'information, mais aussi pour
l'organisation de l’entreprise.
La responsabilité du système d'information passe de
l'informatique, qui la détenait traditionnellement, aux métiers qui définissent son
contenu fonctionnel et maîtrisent sa modélisation. .
L'informatique cesse d'être un centre de coûts et devient
centre d'investissement au service des métiers. L'entreprise renonce à la notion d'
" enveloppe informatique ".
Le soutien aux utilisateurs devient l'activité prioritaire de
l'informatique, alors qu'il confine aujourd'hui parfois au bizutage. Les éléments
essentiels du système d'information sont les processus et les objets, non plus les
applications.
Organisation |
M1 |
M2 |
Responsabilité
du SI |
Informatique |
Métiers |
Economie de
l’informatique |
Centre de coût |
Centre
d’investissement |
Priorités de
l’informatique |
Développement
Exploitation |
Soutien aux
utilisateurs |
Eléments du SI |
Applications |
Processus
Objets |
Ces changements de priorités ont des conséquences sur la
façon dont les informaticiens perçoivent leur rôle. Ils impliquent une double
professionnalisation : celle des maîtres d’ouvrage, qui doivent apprendre à
modéliser leurs processus ; celle de l’informatique, qui doit maîtriser les
technologies objet et les délicates architectures (passerelles avec le monde ancien,
" middleware ") nécessaires pour les rendre efficaces.
Transition de l'organisation
L'approche par les processus fait passer l'entreprise du
contrôle a priori (" le chef signe tout ") au contrôle a posteriori
(" on agit d'abord, on fait le débriefing ensuite "), de l'opacité
à la transparence (les retards deviennent visibles, qu'il s'agisse de la signature du
décideur ou du travail de l'exécutant), de la rétention à la diffusion
d'information.
| Contrôle |
A priori |
A posteriori |
| Visibilité |
Opacité |
Transparence |
| Circulation de l’information |
Rétention |
Diffusion
Contrôle d’accès |
| Equipement des utilisateurs |
Terminal passif |
PC en réseau |
| Communication |
Téléphone
Télécopie
Réunion |
les mêmes,
plus :
Messagerie
Documentation électronique
Workflow
Forum |
Il ne faut pas sous-estimer les difficultés de cette
évolution. Ceux qui pratiquent la rétention d'information et tirent parti l'opacité des
procédures ne sont pas pour autant de mauvaises gens : ils se sont adaptés à
l'entreprise et se protègent contre son comportement spontané. Passer de M1 à M2
suppose, pour eux, une traversée du désert pendant laquelle ils ne bénéficieront plus
des protections que comporte M1 et n'auront pas encore atteint l'équilibre que permet M2.
L'exhortation morale serait ici dérisoire : cet effort n'est
raisonnable que si chacun comprend qu'il peut y gagner personnellement. La communication,
au sens médiatique du terme, est un épisode crucial de la migration. Il faut susciter
l'espoir, éveiller l'intuition, avant de chercher à régler les problèmes techniques :
ils se régleront souvent d'eux-mêmes (ou plutôt ils seront réglés dans la foulée) si
l'espoir est présent.
Processus et système d'information
Dans M1, la définition des applications repose sur l'"
expression de besoins ". Celle-ci suppose une interprétation du travail à faire par
les utilisateurs, mais cette interprétation n'est pas nécessairement explicite et reste
donc abstraite. Rien ne garantit qu'elle permettra un bon contrôle du processus
puisqu'elle n'est pas construite à cette fin.
Si l'on considère les processus, on part non de la question
" quels sont les résultats qu'il me faut pour travailler ", mais de la question
" comment est-ce que je travaille " : on découvre alors que tel
processus ne boucle pas, ou n'est pas contrôlable, ou comporte une redondance (un même
travail repris plusieurs fois), que certains points sont fragiles (lorsqu'une décision
dépend d'un avis externe dont le délai n'est pas contrôlable). Structurer le processus
rend visibles certains phénomènes : un acteur doit répondre à un message dans un
délai donné, ou bien la décision lui échappera.
Système d'information et système informatique
Le système d'information est essentiellement sémantique et
fonctionnel ; il est défini par un " modèle complet " qui fait
abstraction des moyens techniques. La maîtrise d'ouvrage doit se doter d'une expertise
spécifique, fonctionnelle, garantissant la pertinence des demandes en regard des
exigences du métier.
Le système informatique, par contre, organise ces moyens ; il
choisit les plates-formes, langages, interfaces, architectures (centralisée, client
serveur à deux ou trois niveaux), la localisation des traitements et mémoires, les
niveaux de conservation des données. Il repose sur une expertise attentive à la
diversité des outils du marché, aux innovations, à la pérennité des solutions.
Dans M1, la frontière entre maîtrise d'ouvrage et maîtrise
d'œuvre était confuse : certes la première était responsable de l'expression des
besoins, et la seconde de la réalisation technique ; cependant la solidarité des
applications, et donc du système d'information, se concrétisait au sein de
l'informatique. La tentation était alors grande de confier à celle-ci plus qu'une
mission de maîtrise d'œuvre, et d'en faire le concepteur du système d'information
fonctionnel, en se substituant aux utilisateurs pour définir leurs besoins.
Dans M2. la séparation devient claire. À l'un la
responsabilité du modèle complet, à l'autre celle de la solution technique. Cette
répartition n'interdit pas le dialogue : la maîtrise d'ouvrage peut s'intéresser aux
solutions techniques, le maître d'œuvre avoir des idées sur ce qui est utile au
plan fonctionnel. Cependant à ce dialogue succède la décision, et alors chacun doit
prendre ses responsabilités propres.
Annexe du chapitre XI : Techniques du système d'information
Cette annexe regroupe des indications permettant de décrire
l'évolution d’un système d'information. Elle est écrite pour le lecteur qui, sans
être un expert, s'intéresse assez à la technique pour chercher à la comprendre.
1. " Client-serveur"
Le terme " client-serveur " (ou C/S) concerne le
partage du travail entre l'ordinateur de l'utilisateur final (le " PC ", que
l'on appelle aussi " poste client ") et l'ordinateur central que l'on appelle
" serveur ".
Le C/S signifie au minimum qu'un élément du réseau - le
client - envoie une requête à un autre élément du réseau - le serveur - qui envoie au
client la réponse à sa requête.
Dans des versions plus évoluées, la gestion des données et la
logique applicative peuvent être réparties entre serveur et client de façon à
optimiser rapidité de réponse, fiabilité et dépenses télécoms.
Le C/S peut aussi être défini comme un mode de développement
applicatif tirant parti des possibilités offertes par les réseaux, les SGBDR répartis,
les interfaces graphiques et les technologies objet. Les langages les plus utilisés sont
Perl ou Java (pour les " serveurs " sous Unix) et C++ ou Java (pour les
" clients ").
Le C/S est difficile à mettre en œuvre lorsque les
plates-formes techniques, (langages, systèmes d'exploitation, machines) sont
hétéroclites : c’est le cas de la plupart des grandes entreprises dont le
système informatique s'est bâti par couches historiques successives, ou en achetant des
entreprises sans mise en ordre du système d’information. Il est alors utile de
recourir à l'architecture à trois niveaux (on dit souvent " trois tiers ", par
une traduction fallacieuse de l'anglais "three tiers "), en intercalant entre le
client et le serveur une couche de "middleware " qui gère les difficiles
questions de routage des messages, transcodage, concurrence entre mises à jour etc. Le
modèle à trois niveaux s'impose dans la plupart des cas, et le " middleware "
devient la couche la plus importante (et la plus délicate) de l'architecture C/S.
Historique
Années 60 : les ordinateurs sont de grosses machines
installées dans des locaux sécurisés et climatisés. Les données et commandes sont
saisies sur des cartes perforées, les résultats sont imprimés sur des listings, les
délais sont longs.
Années 70 : on installe les " terminaux passifs "
auxquels certaines entreprises resteront fidèles pendant 20 ans. On tape les
instructions, le terminal les envoie via un réseau à l'ordinateur, et celui-ci répond.
Ça va plus vite.
Années 80 : le micro-ordinateur arrive. On apprend à le mettre
en réseau et à le faire communiquer avec l'ordinateur central.
Années 90: les prix des PC baissent, leurs performances
augmentent, les écrans austères de l'informatique font place à des interfaces plus
commodes : fenêtres, boutons, menus déroulants, aides en ligne, souris, écran couleur
haute définition, image animée, son stéréo, etc. C'est le " multimédia ".
La dissémination de puissance que représente l'éparpillement
des PC est irrésistible en raison de la déséconomie d'échelle qui caractérise
l'informatique (cf. chapitre VI). S'il y avait économie d'échelle, celle-ci resterait
centralisée.
Étapes du " client-serveur "
Première étape : utiliser l'interface du micro-ordinateur
pour améliorer la présentation des applications. Vu de l'ordinateur central, le PC se
comporte comme le terminal passif d'autrefois ; il n'est utilisé que pour améliorer la
forme des écrans, qui devient plus plaisante. C'est le " revamping ".
Deuxième étape : utiliser la puissance du micro-ordinateur
pour traiter les données. Il partage le travail avec l'ordinateur central, devenu "
serveur ", et dont la charge est allégée d'autant. La communication entre "
client " et " serveur " emprunte le réseau qui relie plusieurs "
serveurs " se partageant le travail. Le " client-serveur ", ce n'est rien
d'autre que cette architecture.
Étape ultime éventuelle : le " serveur " ne sert
plus qu'à gérer et stocker les données, tout le traitement étant fait par le "
client ". On est arrivé au maximum de la décentralisation de la puissance.
La " migration "
L'architecture centralisée était bonne il y a vingt ans,
lorsque les PC n'existaient pas et que les compétences en informatique étaient rares. La
déséconomie d'échelle et la banalisation des compétences l'ont rendue obsolète. Elle
continue cependant à dominer dans les entreprises : passer au " client-serveur
" suppose de réécrire les applications, et c'est coûteux. La migration vers le C/S
s'étale sur plusieurs années (huit ans selon Forrester Research).
40 % du travail des informaticiens est consacré au maintien de
systèmes fatigués et rigides. Les nouveaux systèmes ont besoin des vieilles données,
qui se trouvent dans les bases de données des anciennes applications.
Avec le " client-serveur ", l'" intelligence
" (les programmes) est en partie installée sur le PC et se trouve donc proche des
utilisateurs; ils peuvent utiliser un serveur local pour faire tourner des applications
indépendantes de l'informatique centrale. Il en résulte un changement de l'organisation
du système d’information.
Les entreprises qui ont " migré " sont satisfaites.
Le système d'information gagne en souplesse, performance et fiabilité, ce qui contredit
un argument souvent avancé en faveur des grands systèmes. Toutefois la carence en outils
d'administration rend difficile l'explication des incidents, et la maîtrise du middleware
suppose des compétences élevées.
Aller vers le " clients-services "
L'enjeu essentiel du " client-serveur ", c'est une
baisse de coût. Croire qu'il fera à lui seul " bouger " l'entreprise est une
illusion. Ici la terminologie trompe, notamment les connotations du mot " client
".
L'enjeu principal pour l'entreprise n'est pas de savoir comment
partager des applications entre PC et serveur, mais de mettre efficacement en relation les
vrais clients, c'est-à-dire les utilisateurs internes et les clients de l'entreprise,
avec les services que celle-ci leur offre.
Il faut dépasser l'horizon technique du " client-serveur
" pour embrasser l'ambition du " client - services ". On quitte ici
les questions d'architecture informatique, légitimes mais limitées, pour entrer dans
l'architecture du système d'information.
2. Langages " orientés objet"
Les langages de programmation dits " orientés objet "
sont devenus essentiels pour l'informatique. Si leur logique est simple, le vocabulaire
les entoure d'un mystère que nous allons essayer de dissiper.
Structure applicative du système d'information
Un système informatique fonctionne de la façon suivante : des
faits du monde réel (événements) font l'objet de mesures codées sous forme de "
données " ; ces données sont entrées dans le système informatique (" saisie
"), puis traitées par des fonctions qui les transforment (addition, calcul de
ratios, etc.). On obtient ainsi des résultats transmis à l'être humain à travers des
interfaces.

La complexité des traitements interdit de maîtriser un
système aussi global. On le découpe donc en " applications ".
Idéalement, il faudrait pour définir ce découpage établir le
tableau croisant variables d'entrée et résultats, classer ce tableau de façon à lui
donner une structure bloc-diagonale (beaucoup d'échanges à l'intérieur d'un même bloc,
peu d'échanges entre blocs différents). A chaque bloc correspondrait une application.
Cela se fait en pratique de façon empirique.
Organisation du système informatique en applications

Identification des " objets "
Le schéma ci-dessous a la forme d'un graphe où les arcs
représentent des échanges de données et les sommets les traitements appliqués aux
données. Il arrive que dans un tel graphe on retrouve de façon répétitive le même
sous-ensemble de fonctions et de données.
C'est cet ensemble que l'on va appeler " objet ". Le
terme " objet " est un faux ami, car il s'agit non d'un " objet " au
sens du langage courant, mais d'un petit programme informatique. Il est toutefois souvent
utile de définir cet objet informatique de telle sorte qu’il corresponde à un être
du monde réel, dont il constitue une abstraction (puisqu’il ne comprend bien sûr
qu’une partie des données que l’on pourrait observer sur un être réel,
celles-ci étant en nombre infini).
Objet, encapsulation, interfaces, messages

L’idée à l'origine de la notion d'objet est ancienne: si
le même bout de programme se retrouve souvent dans les applications, il convient de
l'identifier, de le stocker quelque part et de le réutiliser plutôt que de l'écrire à
plusieurs reprises. L'avantage des langages orientés objet est de systématiser la "
réutilisabilité ".
Certains de ces bouts de programme se ressemblent beaucoup sans
être identiques (par exemple un dossier de salarié a toujours la même structure, mais
son contenu varie d'un salarié à l'autre). On dit qu'ils forment une " classe
". Lorsqu'une classe utilise des fonctions déjà programmées dans une autre classe,
on dit qu'elle " hérite " de cette classe. On distingue les classes selon
qu'elles concernent les interfaces, la communication, les traitements, etc.
Lorsqu'une donnée entre dans un objet, ou qu’elle en sort,
elle passe par une " interface ". L’objet est donc défini par ses
interfaces et par les données et fonctions qu'il contient.
Nous avons introduit les termes " classe ", "
héritage ", " réutilisabilité ", " interface ", "
message ", qui se comprennent bien. Les spécialistes ont introduit un vocabulaire
qui crée parfois la confusion : ce que l'on appelle " variable " en
mathématiques, ils l'appellent " attribut ". Voici une petite liste des
transpositions de vocabulaire qui gênent le plus la communication :
Quand on
entend… |
… il faut
comprendre : |
Objet |
Petit programme
informatique |
Attribut |
Variable |
Instanciation |
Donner une
valeur à une variable |
Méthode |
Fonction (au
sens mathématique) |
Encapsuler |
Introduire
fonctions et variables dans l’objet |
La modélisation des processus
L’expression des besoins, nécessairement antérieure à
toute programmation, se fait commodément en utilisant le formalisme de l’orienté
objet : on identifie les activités qui s’enchaînent dans les processus, puis
les objets dont ces activités ont besoin, puis les conditions de stockage et
d’accès aux données qui procurent la performance souhaitée. Les premières phases
de cette opération utilisent le langage UML (cf. contenu du chapitre).
La programmation orientée objet
Les programmes écrits en langage orienté objet sont
constitués d'objets qui communiquent en échangeant des messages. Un programmeur qui a
l'expérience de l'orienté-objet est familiarisé avec des bibliothèques contenant les
classes les plus utiles. Il procède comme ceci :
- après avoir analysé le problème posé, il charge les classes dont il aura
besoin. Il les utilisera pour limiter le travail de programmation de nouveaux objets ;
- il spécifie les objets et les messages qu'ils doivent échanger.
La programmation orientée objet est alors comme une
construction en kit utilisant des éléments préfabriqués. Un programmeur qui a
l'habitude de tout faire lui-même, et qui ne connaît pas les pièces du kit, est perdu
devant cette façon de procéder. Elle est par contre pratique pour les débutants, et ils
l'apprennent vite.
L'échange des messages est un point délicat : lorsqu'un objet
émet un message, il faut en effet qu'il sache trouver l'objet destinataire du message, ce
qui suppose résolues de délicates questions d'adressage et de routage. Elles sont
traitées par une couche de middleware spécialisée, le " broker ", à laquelle
tous les messages sont adressés et qui a la responsabilité de trouver leur destinataire.
Un programme écrit en langage orienté objet est plus clair,
mieux documenté, plus facile à faire évoluer qu'un programme traditionnel. Le travail
de conception initial est lourd, mais les coûts de maintenance sont divisés par un
facteur de l'ordre de 5.
3. Datawarehouse
La mise des données à la disposition des utilisateurs s'est
d'abord faite en utilisant des Infocentres, bases de données dans lesquels les
applications déversaient des résultats sélectionnés. Dans un Infocentre, une donnée
nouvelle écrase l'enregistrement ancien, ce qui ne permet pas de constituer une série
chronologique.
Le Datawarehouse, lui, enregistre l'information sous forme de
séries chronologiques. Par ailleurs, il est outillé pour calculer des agrégats (ventes
par ensemble de produits, par région, par pays, etc.). Ces agrégats sont placés dans
une structure en tableau pour faciliter les totalisations et présentations graphiques.
Comme ce tableau a généralement plus de deux dimensions, on l'appelle " hypercube
".
L'ambition d'un Datawarehouse est de produire, à partir de
données nombreuses mais peu consultées par les utilisateurs, des agrégats peu nombreux
mais fréquemment consultés. L'image souvent utilisée est celle d'une pyramide dont la
large base est constituée par les bases de données, peu consultées, et le sommet par
quelques données agrégées, jouant un rôle central dans l'évaluation de l'activité de
l'entreprise. Les outils de Datawarehouse facilitent la gestion de cette pyramide : aide
au choix de méthodes d'agrégation pertinentes, à l'écriture et à la documentation des
règles d'agrégation, gestion des tables de passage entre nomenclatures, etc.
Le Datawarehouse n'est complet que s'il outille aussi les
tâches " éditoriales " de sélection, présentation, commentaire et diffusion
de données agrégées. L’image qui s'impose n'est plus alors celle d'une pyramide,
mais d'un " diabolo " dont la moitié haute représenterait les
tâches éditoriales.
Datamining
Le " Datamining " vise à identifier les données
détaillées qui expliquent l'évolution d'un agrégat. Les techniques d'analyse
discriminante, de segmentation etc. sont ici utiles.
Exemples vécus de datamining
Exemple 1 : une compagnie aérienne constate que ses ventes sont
anormalement faibles dans une ville par rapport à celles d'un concurrent. Le datamining
permet de repérer l'agence de voyage responsable et une intervention commerciale permet
de supprimer l'anomalie.
Exemple 2 : une entreprise d'assurance constate que 25 % de sa
marge provient de 2 % de ses clients, et qu'elle est en train de perdre des parts de
marché sur ce segment. L’analyse révèle que ce segment comporte des entreprises
abonnées à plus de deux revues économiques. L'assureur fait former ses vendeurs à
l'économie; ils sont ainsi capables de trouver les mots qui restaurent la confiance de
ces clients et de redresser la part de marché.
On représente souvent le datamining comme une démarche
descendante : elle part du sommet de la pyramide des données pour chercher à la base une
information à forte valeur ajoutée, éclairant la cause d'une anomalie constatée dans
un agrégat.
Observons que le datawarehouse et le datamining sont des
démarches descriptives, non des démarches explicatives : pour pouvoir
passer de la description à l’explication, il faut leur ajouter des travaux de
recherche opérationnelle visant à construire et tester des modèles.
4. Intranet
On a utilisé successivement les termes " groupware ",
" collectique " et finalement " Intranet " pour désigner un
ensemble de logiciels de bureautique communicante élaborés pour faciliter le travail de
groupe dans les entreprises.
Les points de départ de la collectique et du système
d'information sont très éloignés. La collectique vient de la bureautique, qui a été
marquée par l’utilisation individuelle d'applications d’abord purement locales
(tableur, traitement de texte, grapheur) et caractérisée par l'individualisme, voire
l'anarchie, chacun s'entichant des logiciels dont il avait l'habitude. Le besoin
d'échanger des fichiers, accéléré par la mise en réseau des PC, a poussé à la
standardisation (dans une même entreprise tout le monde devrait utiliser le même
traitement de texte).
La messagerie et l'agenda partagé ont inauguré l'ère de la
collectique. Les bases documentaires, forums et " workflows " ont confirmé
cette évolution.
Alors se constituent sur les réseaux locaux de petits systèmes
d'information à base bureautique. La communication entre serveurs les étend à
l'entreprise, indépendamment de la distance entre établissements, et leur confère
parfois une importance qui surprend en regard de leur modeste origine. En utilisant à
l’intérieur de l’entreprise les mêmes protocoles que ceux de l’Internet
(TCP/IP pour la communication, HTML et XML pour les documents et applications),
l’entreprise facilite l’ouverture de son système d’information -moyennant
sécurisation et contrôle d’accès - à ses fournisseurs, partenaires et
clients : on parle alors d’Extranet. Enfin, elle peut ouvre à ses salariés
l’accès à la messagerie et à la richesse documentaire du Web sur l’Internet.
Par ailleurs, le système d'information devient accessible à
partir des applications de collectique. Des passerelles ont été développées entre
produits de collectique et système d'information : il est possible d'alimenter un SGBDR
avec des données structurées saisies ou produites dans le cadre d'une base documentaire
ou d'un " workflow ", et inversement un SGBDR peut envoyer des messages
déclenchant la création ou la mise à jour de documents. Le langage XML apporte
simplicité et puissance à cette opération.
La collectique y gagne en rigueur et solidité. Les bases
documentaires deviennent cohérentes, solidaires, y compris dans les entreprises
multisites. Les incohérences ne subsistent que pendant les délais d'émission et
réception des messages ou les délais de réplication ; cet inconvénient est
souvent négligeable.
L’entreprise E construit deux bases documentaires:
- un annuaire téléphonique sur une plate-forme Domino : à chaque personne est associé
un document où figurent nom, fonction, adresses (bureau, téléphone, télécopie,
messagerie), photographie etc. Des vues permettent des recherches selon divers critères
(alphabétique, par fonction, service, localisation etc.). Cet annuaire constitue une
documentation sur les personnes et des champs à accès contrôlé sont ouverts pour les
besoins de la GRH (carrière, curriculum vitae etc.). En particulier, la liste des projets
auxquels participe une personne est mentionnée ;
- une application de suivi de projet : à chaque projet est associé un ensemble de bases
documentaires à accès contrôlé, contenant la liste des personnes qui ont participé ou
participent au projet.
Pour que les informations fournies par ces deux bases soient
cohérentes, il faut que la mise à jour d'une liste de personnes dans (b) déclenche une
mise à jour dans (a). Ceci suppose une définition commune de la liste des projets et des
noms des personnes, donc un modèle conceptuel de données, ainsi qu'une administration
des échanges entre bases documentaires. Ces deux bases constituent donc un petit système
d'information.
La relation avec le système d'information, confiée auparavant
à un expert en SQL, devient accessible à ceux qui ont appris à utiliser les interfaces
commodes de la collectique. L’accès au système d'information se démocratise, ce
qui oblige à administrer le contrôle d'accès et la qualité des données de façon
rigoureuse.
Commentaire des données
On croit parfois que la connaissance réside dans les données.
Il n'en est rien : il faut encore les interpréter et les commenter. Quoi que l’on
affirme souvent le contraire, les données à elles seules ne " parlent "
jamais. Savoir que l'effectif de la population française est de 60 millions n'apprend
rien si ce nombre n'est pas situé dans une série chronologique ou comparé à d'autres
(statistiques relatives à des pays comparables, densités de populations, fécondité,
pyramide des âges etc.)
Un texte " littéraire " est donc nécessaire pour
transmettre la connaissance fournie par le quantitatif. La décision elle-même, qui se
réduit toujours à une réponse par oui ou par non à une question (doit-on faire tel
investissement ? doit-on participer à telle entreprise ?), relève du qualitatif quel que
soit l'échafaudage quantitatif utilisé pour l'instruire.
L'interprétation des données est fondée sur :
(a) les définitions : un tableau de nombres est
incompréhensible si l'on ne connaît pas les définitions de ses lignes et colonnes.
(b) l'examen des propriétés statistiques : on doit réaliser
des calculs (moyennes, variances, etc.) et utiliser des représentations graphiques pour
rendre apparentes les structures sous-jacentes des données.
(c) la confrontation des données avec d'autres
informations : le SGBDR est souvent loin de donner l'information dont on a besoin
pour alimenter un modèle, fût-il simple ; il faudra l'enrichir par le recours à des
sources ou expertises extérieures. L'interprétation des cours du pétrole requiert la
prise en compte de la situation politique au Moyen-Orient et relève d'une expertise
délicate.
(d) la confrontation des données avec un modèle théorique :
elle fournit des hypothèses sur les relations fonctionnelles et/ou causales entre
données : toute interprétation doit comporter la présentation explicite d'un modèle,
fût-il simple.
L’évolution du trafic téléphonique ne peut être interprétée
que si l'on dispose d'un modèle formalisant les effets du revenu des diverses catégories
d'utilisateurs, du prix du téléphone et des services concurrents, des campagnes de
publicité, de la diversification des services qui recourent au réseau téléphonique, de
l'évolution tendancielle, etc. Tout commentaire sur les données qui ne passe pas par
l'utilisation d'un modèle (qu'il faut parfois spécifier et dont il faut estimer les
paramètres pour l'occasion) sera naïf et souvent erroné.
Il y a une intention au départ de tout examen des
données. Les données ne sont jamais abordées d'un point de vue contemplatif, pour le
plaisir (bien austère) de regarder des nombres. On les aborde parce que l'on veut
vérifier, contrôler, parce que l'on a quelque chose à faire. Cette intention oriente le
choix du modèle d'interprétation, détermine les exigences de précision, suscite les
recoupements d'expertise etc. La démarche technique est correcte si elle est pertinente
en regard de cette intention.
Le commentaire des données est un texte qui donne leur place
aux données elles-mêmes, à des graphiques, à de petits tableaux sélectifs, enfin à
des phrases qui expriment en clair les conclusions de l'expert. Rédiger des commentaires
sobres et clairs, destinés à des clients divers, c'est une tâche éditoriale délicate.
L’entreprise E a équipé un " call center " (assistance
téléphonique) d'un " référentiel ", base documentaire où sont stockées et
classées les questions et les réponses. Le but premier de ce référentiel est de
permettre aux opérateurs de répondre directement à une forte proportion des questions,
sans faire appel aux experts. Mais en outre l'exploitation statistique de ce référentiel
fournit des informations précieuses ; elle permet des éditions diverses selon que l'on
s'adresse à un chef de ligne de produit, à un directeur régional, au responsable de la
force de vente, au responsable de la formation etc.
Des données sans commentaire sont muettes ou sources de
contresens. Seul le commentaire autorise à les mettre dans les mains de l'utilisateur
final, et lui permet d'en tirer profit. Il est donc important de disposer d'outils aidant
à faire circuler les commentaires, à les mettre à la disposition de l'utilisateur:
c'est l'apport de l'Intranet lorsqu'il est associé au système d'information. Il permet
alors d'établir collectivement (rédaction coopérative), discuter (forum), valider
(workflow), classer, partager les commentaires (base documentaire) tout en assurant le
contrôle d'accès à l'information. Des commentaires de commentaires facilitent sa
synthèse. Des outils de diffusion sélective permettent à chacun de recevoir les
informations qui lui sont utiles. L'accès à l'information est ouvert à ceux qui ont le
droit de la connaître. Ceci s'accompagne de l'introduction d'une certaine rationalité
dans l'entreprise, et contrarie l'exercice capricieux ou arbitraire du pouvoir. Cette
dernière conséquence explique que l'articulation entre l'Intranet et le système
d'information puisse rencontrer des résistances.
|