|
De la programmation impérative à la
technologie objet
28 décembre 2002
Tout programme consiste en la définition (1) des
structures de données qui seront manipulées (saisies, consultées, soumises à
des traitements) ; (2) des traitements qui seront appliqués aux données ; (3)
enfin, d'une succession (comportant éventuellement des boucles, fourches et
chemins parallèles) d'appels de données et de traitements.
Les langages de programmation se distinguent par
la façon dont ils réalisent et articulent ces trois éléments, et notamment
par les règles de nommage et d'adressage qui permettent de localiser et d'appeler
données et traitements.
Selon la thèse de Church-Turing, tout langage de programmation non trivial
équivaut à une machine de Turing ; il en résulte
que tout programme que l'on peut écrire dans un langage pourrait être également écrit dans
n'importe quel autre
langage. La
différence entre les langages ne réside donc pas dans ce qu'ils permettent de
programmer, mais dans ce qu'il est facile, commode de programmer
avec chaque langage : cette différence est d'ordre non pas logique, mais
pratique.
Elle n'en est pas moins importante, et il faut relativiser la thèse de
Church-Turing. Utilisons une analogie : il est certes également possible
de traverser la Seine en marchant sur un
câble d'acier ou sur le pont de la Concorde ; mais pour marcher sur le premier il faut
être un funambule bien entraîné, alors que le second est à la portée d'un promeneur. Il en
est de même pour les langages. Tout ce que l'on fait avec un langage de
programmation objet (ou "orienté objet", comme on dit souvent)
pourrait être
fait en programmation impérative ; mais la sécurité n'est pas la même dans
les deux cas, ni l'évolutivité (possibilité de faire évoluer le programme
pour un coût raisonnable).
Programmation impérative
Si l'on peut tout faire avec un
langage de programmation - et notamment faire en sorte qu'une application
respecte toutes les contraintes de qualité évoquées dans "Découpage du système informatique en
applications" - ce sera plus ou
moins difficile selon la démarche de modélisation et le langage de
programmation que l'on utilise (la "modélisation", c'est la
définition des structures de données et des traitements ; elle est logiquement
et chronologiquement antérieure à la programmation proprement dite). Il est
trop facile de
réaliser des "plats de spaghetti" en Fortran, en Cobol ou en C ;
Pascal incite à la modularité, ce qui encourage à rédiger des programmes clairs et bien documentés : mais il est peu utilisé par les programmeurs
professionnels.
Ces quatre langages sont destinés à la
programmation impérative, celle qui correspond à l'intuition la plus immédiate pour un informaticien :
il s'agit de programmer d'une part les structures de données, d'autre part les traitements qui transformeront
les données d'entrées en résultats. La
programmation impérative se prête à la mise en commun des
traitements (le traitement "mise à jour" peut être utilisé par
les fonctions "créer" et "supprimer") comme des
données, éventuellement partagées avec d'autres applications (elles sont alors classées dans une "base de données").
Quoique données et traitements soient
reliés par nature, puisque
le logiciel fait traiter les données par lordinateur, lapproche la plus
courante a été de concevoir les bases de données séparément des programmes
de traitement en utilisant des outils de modélisation et de documentation différents.
Certes il est avantageux de traiter ainsi séparément des problèmes de nature différente, mais
cela comporte un inconvénient : si l'application est
compliquée et si les besoins évoluent (création de nouveaux produits,
introduction de nouveaux segments de clientèle, de nouveaux types de
partenaires etc.), les mises à jour obligeront à
réécrire une grande partie du code au risque d'introduire des erreurs qu'il
faudra alors corriger.
Rien n'empêche bien sûr d'organiser la
programmation de sorte que les évolutions soient aussi
simples que possible : cela suppose, en pratique, de rapprocher données
et traitements. Prenons un exemple : si une entreprise a défini la structure de
données et les traitements pour traiter des abonnés à un service, et si elle veut
par la suite que l'application puisse traiter aussi des acheteurs de matériel, il
lui faudra introduire une nouvelle structure de données et de nouveaux traitements
et cela obligera à réécrire une partie de l'application. Mais si l'on
a pris la précaution de définir une structure de données "client" capable
de comporter comme cas particuliers des abonnés, des acheteurs de matériels ou
encore d'autres types de clients,
il sera possible d'introduire un nouveau type de client sans écrire autre chose
que le code strictement nécessaire. Cependant, comme certains traitements s'appliquent à
l'abonné, d'autres à l'acheteur, il faudra que les traitements associés à
la structure de données "client" soient paramétrés par
le type de client. Il sera donc utile, pour la clarté du code, d'écrire près
l'un de l'autre les données et traitements relatifs à la structure
"client". Nous sommes alors proches de la définition de que les
informaticiens appellent un objet.
Ce petit exemple montre comment les
informaticiens ont très naturellement été conduits, pour améliorer l'évolutivité des applications, à
concevoir des langages dans lesquels les
données qui décrivent un dossier sont insérées dans le même module que les traitements qui
leur sont appliqués ; pour utiliser les termes
consacrés, on dira que données et traitements sont "encapsulés dans
le même objet".
Ainsi les langages de programmation objet (ou
"orientée objet") sont la conséquence ultime de la modularisation du
logiciel, démarche qui vise à maîtriser sa production et son
évolution. Mais malgré cette continuité logique ces langages ont apporté en
pratique un profond changement dans
l'art de la programmation : même si la programmation objet n'est que de la programmation
impérative bien organisée,
elle implique en effet un changement de l'attitude mentale du programmeur.
En programmation impérative, la qualité des méthodes
devait être apportée par le programmeur lui-même, un programmeur peu rigoureux
ayant toute liberté de programmer un "plat de spaghetti" peu
évolutif. En
programmation objet, une part de la rigueur est incorporée dans le langage, tout comme un pont est muni de
garde-fous.
Cela n'exclut pas le risque d'erreur : même si un pont est muni de garde-fous,
quelqu'un qui veut se jeter dans la rivière, tourner indéfiniment en rond sur le pont ou
le franchir en marchant sur les mains pourra le faire ; mais l'utilisateur de bon
sens, qui veut tout simplement traverser le pont, le traversera en marchant tout
simplement.
Programmation objet
Le mot "objet" est un faux
ami, car il oriente dans une mauvaise direction l'intuition de celui qui
l'entend pour la première fois et il faut lutter contre cette intuition pour
comprendre de quoi il s'agit (voir "A propos de l'utilisation du terme "objet" en
informatique"). Pour faciliter la compréhension, nous allons recourir
à des analogies.
Toute entreprise doit gérer des "individus"
qui composent des "populations", en utilisant ces
termes selon le sens quils ont en statistique : les "individus" peuvent être des personnes
physiques ou morales, pièces de rechange, machines, établissements, commandes,
factures, etc. Les "populations" sont donc des ensembles de
personnes, de pièces de rechange, etc. : une population est un ensemble fini
d'individus qui possèdent des caractéristiques analogues.
Dès que les entreprises se sont
organisées (voir "Évolution du SI : du
concept au processus"), elles ont construit des "dossiers"
pour décrire les individus ; à chaque population correspondait un type de
dossier (ou de formulaire, ou de questionnaire) définissant une liste de
données, à chaque individu correspondait un dossier rempli, chaque case
contenant la valeur d'une donnée observée sur l'individu. A chaque dossier
étaient associés également quelques calculs : vérifications et recoupements
pour s'assurer de l'exactitude des données ; évaluation des taxes, droits,
montants de facture, etc.
La modélisation objet, même si
elle semble nouvelle, revêt cette
démarche traditionnelle d'un vocabulaire nouveau. La
"classe", description de l'individu type d'une population, n'est rien
d'autre qu'un dessin de dossier dans lequel on aurait fait figurer, outre la
définition des données (que l'on appelle "attributs"), celle des traitements
qui leur sont associés (que l'on appelle "opérations" ou "méthodes"). Le dossier
relatif à un individu, dans lequel sont inscrites ("instanciées")
les valeurs des données observées sur cet individu, sera nommé "objet".
Ce vocabulaire provoque des confusions. La
"classe" du langage objet n'est pas la "classe" d'une
classification (qui est, elle, l'un des éléments d'une
partition opérée sur une population) ; l'"objet" du langage objet,
qui représente un individu, n'est pas l'"objet" de la philosophie,
qui est l'individu lui-même ; les "méthodes" du langage objet ne
sont pas des méthodes au sens où l'on dit "méthode de travail",
mais des fonctions au sens mathématique du terme, comme lorsque l'on écrit y =
f(x).
Lorsqu'un informaticien dit
"un objet est une abstraction", cette phrase est exacte car il parle d'un objet au sens
de la modélisation objet : en effet la
liste des données que contient cet objet, étant
sélective, est "abstraite" de l'ensemble indéfini
des données que l'on pourrait observer sur un même individu. Mais comme le
philosophe entend par "objet" l'individu lui-même, cette phrase est
pour lui un non-sens. Toutefois
le philosophe aurait tort d'en rester à cette impression
superficielle : s'il accepte de comprendre le vocabulaire de la modélisation
objet, il verra que celui-ci ne fait qu'organiser de façon
ingénieuse la démarche d'abstraction et de conceptualisation qui,
depuis Aristote, est le fondement même de la philosophie.
- *
- * *
- Le modélisateur choisit la
liste des attributs à retenir pour caractériser une classe. Ce choix est
guidé par les exigences de pertinence et de sobriété du
système d'information (Voir "Découpage du système informatique en
applications") : il faut connaître les données utiles à l'action que
l'on entend assister, et elles seules.
Supposons que pour une application
particulière on ait défini la classe "automobile" et retenu la
liste suivante des attributs et des méthodes :
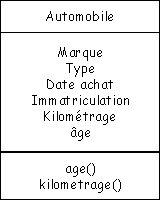
Il est d'usage de terminer le nom
d'une méthode deux parenthèses successives.
Ici, nous supposerons qu'age() calcule l'âge d'une automobile par différence entre la date d'achat et la date du jour
et que kilometrage() assure la mise à jour du
kilométrage cumulé par saisie d'un kilométrage hebdomadaire.
A chaque automobile sera associé un "objet" où figurent les
instances des divers attributs. L'objet comporte (1) un identifiant qui permet de
désigner sans ambiguïté l'individu dont il s'agit (ici : numéro du châssis) ; (2) les valeurs des
attributs observées sur cet individu ; (3) les méthodes définies pour les individus de la classe. Voici
l'objet qui
correspond à une automobile concrète :

Les attributs qui caractérisent un objet sont protégés contre
des modifications intempestives : ils ne peuvent être modifiés que si
l'utilisateur emprunte la procédure prévue, que l'on appelle
"interface". La protection ainsi accordée aux données est nommée
"encapsulation". C'est l'un des garde-fous que procure la
programmation objet : en programmation impérative, si l'on n'y prend garde,
les données pourraient être modifiées sans précaution
particulière.
Héritage, polymorphisme,
agrégation
La modélisation objet utilise des
procédés qui permettent d'économiser l'écriture du code et contribuent à
son évolutivité :
Héritage
Certaines populations peuvent faire
l'objet d'une segmentation en sous-populations : c'est le cas
des classes "employés", "client", "produit",
"fournisseur", etc. Chaque sous-population peut être caractérisée
par les mêmes données que la population entière, auxquelles on ajoute des données
propres à la sous-population. Par exemple, si l'on considère la population des
"employés", on peut définir les sous-populations
"managers", "ouvriers", "secrétaires" etc. caractérisées chacune par des données spécifiques,
venant s'ajouter
aux données qui caractérisent les "employés" en général.
Si l'on utilise le langage de la
modélisation objet, on dira que les classes "manager",
"ouvrier", "secrétaire" héritent de la classe
"employé" car elles reprennent ses attributs et méthodes en leur ajoutant
des attributs et méthodes spécifiques.
L'héritage peut être partiel : dans ce cas, seule une partie des
attributs ou méthode de la classe-mère est repris par la classe-fille. Il peut
être simple ou multiple : une même classe peut être sous-classe de plusieurs
classes. Toute modification de la classe-mère entraîne une modification des
classes-filles, sans qu'il soit nécessaire de les reprogrammer. En sens inverse, il arrive que
plusieurs classes puissent être considérées comme filles d'une même classe-mère, ce qui permet de regrouper leurs
caractéristiques communes en créant cette classe-mère.
Le programmeur peut construire rapidement les classes dont il a besoin en puisant dans
le stock des classes existantes, les "bibliothèques". Les bibliothèques
fournies avec un langage objet sont riches ; le premier travail du programmeur sera de sélectionner et charger les classes
utiles,
après quoi la programmation ressemblera un peu au montage d'un
produit vendu en "kit". Le programmeur peut bien sûr constituer une
bibliothèque avec les classes qu'il a définies lui-même, ce qui lui permettra de
réutiliser le code (Nota Bene : cet argument est souvent
évoqué en faveur des langages objet ; toutefois la réutilisation suppose chez
le programmeur une rigueur peu fréquente).
Polymorphisme
Le "polymorphisme"
est, pour une même opération, la faculté de s'appliquer à des objets appartenant à
des classes différentes.
Exemple : pour calculer la
surface dun carré, on utilise la formule S = a2 ; pour un triangle, S = Ah/2 ; pour
un cercle,
S = πR2 ;
pour un trapèze, S = (A + B)h/2 etc. Ainsi la même opération « calculer
la surface » sappuie, selon la figure géométrique considérée, sur
des méthodes différentes.
Si
l'opération calculer_la_surface() est douée de polymorphisme, elle provoquera
lapplication de la méthode adaptée quelle que soit la figure géométrique.
Dès lors le programmeur na plus à se soucier du type de figure auquel cette
opération sappliquera.
Agrégation
L'agrégation indique
qu'une classe est une
composante d'une autre classe. Cela permet de définir des objets composés
d'autres objets, que l'on nomme "packages" ou "composants".
L'une des classes agrégées dans un composant est la classe principale ("main") qui assure les fonctions d'interface
avec le reste du monde et lance les traitements dans les autres classes.
Exemple
: le composant "client" peut contenir une classe "adresse" qui
permet de noter la (ou les) adresses du client. La même classe
"adresse" pourra être utilisée par le composant "fournisseur", le formalisme de l'adresse ne changeant pas selon que
l'on considère l'un ou l'autre des composants.
Écriture et exécution d'un
programme objet
Écriture
Avant d'écrire la première ligne
d'un programme objet, il importe d'avoir défini les classes, attributs, etc.,
c'est-à-dire d'avoir "modélisé" l'application. Ce travail sera fait
soit par le programmeur, qui devra faire valider ses choix par le client, soit par la
maîtrise d'ouvrage qui livrera au programmeur un "modèle métier"
(ou "spécifications générales") proche des préoccupations du
client mais déjà formulé selon les concepts de la méthode objet (classes,
attributs, etc.). L'état de l'art propose d'utiliser, pour cette modélisation,
le langage UML. Puis ce modèle sera progressivement
précisé (voir "Modélisation du processus")
jusqu'à ce que toutes les décisions nécessaires à la production du code
aient été prises.
Le programmeur lance alors, en
s'appuyant sur le modèle, un générateur de code source qui produit
automatiquement de l'ordre de 80 % des lignes ; il restera à les compléter
pour finir l'écriture du programme. Un outil comme Rose de
Rational (http://www.rational.com/products/rose/index.jsp)
permet à la fois d'écrire le modèle, dans ses diverses étapes, et
de générer le code source : ainsi le travail peut progresser de façon
cumulative, sans perte d'information et sans qu'il soit besoin de le réécrire pour
l'adapter à un formalisme
nouveau.
La programmation objet requiert une
réflexion préalable plus longue que
celle, peut-être insuffisante, qu'il est habituel de consacrer à la
programmation impérative. Par contre, une fois le modèle construit, l'écriture du code est plus rapide.
Exécution
Lorsqu'un programme objet est
lancé, l'exécution commence par une des classes (nommée "main",
classe principale). Cette classe envoie des messages vers d'autres classes ou
sollicite une action de l'opérateur humain (ou d'une autre application), ce qui déclenche une
cascade de traitements, messages, affichages sur les équipements
périphériques (écrans, imprimantes etc.) jusqu'à la fin de l'exécution du
programme.
Les objets distribués
Les objets communiquent par des messages
qui transmettent des données ou des appels de méthodes, les adresses étant définies dans l'espace de nommage du programme. L'adressage et le libellé
des messages posent problème lorsque l'on travaille sur des objets
résidant sur des ordinateurs différents ("objets distribués"),
appartenant à des programmes écrits dans des langages différents ou exploités sur des plates-formes différentes. Il faut alors utiliser un "Object
Request Broker" (ORB) : il permet de concevoir des applications où le traitement réalisé sur un ordinateur nécessite l'exécution d'un autre
traitement sur un autre ordinateur. Les objets distribués sur le Web sont
nommés "Web services".
La définition des ORB a nécessité
unee normalisation qui a été assurée par l'OMG (Object
Management Group, www.omg.org, organisation
internationale qui fédère les entreprises concernées par la technologie
objet). L'OMG a défini l'architecture MDA ("Model Driven
Architecture"), dont les
fleurons sont la norme CORBA pour les ORB ("Common Object Request Broker
Architecture") et le langage de modélisation UML ("Unified Modeling Language",
voir "Le
langage UML"). Les outils CORBA relèvent, comme les EAI,
du "middleware" : ils assurent des fonctions de communication
entre programmes et remplissent donc mutatis mutandis une fonction
analogue à celle des commutateurs d'un réseau téléphonique ou des "hubs"
d'un transporteur aérien. .
Articuler la technologie objet
et la programmation impérative
Pour longtemps encore le système
d'information d'une entreprise devra faire cohabiter les applications nouvelles,
écrites en langage objet, et les applications anciennes qui gèrent
séparément les bases de données et les traitements. Il est possible
d'introduire dans un programme objet des êtres qui se comportent comme des
objets quand on les voit du côté du langage objet et qui lancent des requêtes
et appels de traitements vers l'application traditionnelle.
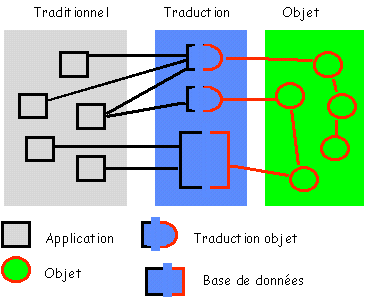
Sun commercialise la plate-forme
J2EE ("Java 2 Platform, Enterprise Edition") qui assure la
communication entre les applications objet, les bases de données et les
applications traditionnelles.
Petit historique de la programmation objet
Les premiers langages de programmation qui
aient
utilisé des objets sont Simula I (1961-64) et Simula 67 (1967), conçus
par les informaticiens norvégiens Ole-Johan Dahl et Kristan Nygaard pour simuler le comportement de systèmes complexes.
Simula permet de traiter
numériquement des problèmes qu'il serait impossible de résoudre de façon
analytique, par des équations explicites. Il a été par exemple utilisé
pour calculer la distribution statistique des durées de traitement des
passagers dans un aéroport, problème qui articule plusieurs
phénomènes aléatoires (rythme d'arrivée des passagers, durée de
l'enregistrement, durée des déplacements dans l'aéroport etc.) ; Simula représente chaque
passager par un objet (nombre de bagages, destination etc.), et après un nombre
suffisant de simulations il fournit les histogrammes des distributions
statistiques recherchées. Simula 67 contenait déjà les objets, les classes,
l'héritage, l'encapsulation etc.
Alan Kay, du PARC de Xerox, avait utilisé Simula dans les années
60. Il réalisa en 1976 Smalltalk qui reste aux yeux de certains
programmeurs le meilleur langage de programmation objet. Pour Alan Kay, chaque objet est comme un petit ordinateur qui
interagirait avec d'autres ordinateurs : « Bob
Barton (...) had said (
) : "The basic principle of recursive design is
to make the parts have the same power as the whole". For the first time I
thought of the whole as the entire computer and wondered why anyone would want
to divide it up into weaker things called data structures and procedures. Why
not divide it up into little computers, as time-sharing was starting to ?
But not in dozens. Why not thousands of them, each simulating a useful structure ? »
(Alan Kay, « The Early History of Smalltalk », History
of Programming Language II, Addison Wesley, 1996, p. 516).
Bjarne Stroustrup a mis au point C++ aux Bell Labs
d'AT&T en 1980. C++, c'est "C with classes", le
langage C doté des outils qui permettent la programmation
objet. C++ deviendra le langage le plus utilisé par les programmeurs
professionnels ; il requiert beaucoup de
savoir faire, car comme C il permet d'agir sur les couches basses (programmer un pilote de disque ou une pile
TCP/IP), possibilité utile pour un industriel mais dangereuse entre les mains
d'un débutant (voir
"Entretien avec Laurent Bloch") et qui n'est d'ailleurs
généralement pas nécessaire
pour programmer une application destinée à une
entreprise.
Java est lancé par Sun en 1995.
Comme il présente
plus de sécurité que C++ il deviendra le langage favori de certains
développeurs professionnels. Un programme en Java peut être soit directement compilé en
langage machine (tout comme un programme en C++), soit d'abord compilé dans un
code intermédiaire, le "bytecode", puis interprété et exécuté sur
chaque machine par une "Java Virtual Machine". Ce dispositif en deux
étapes permet d'exécuter un même programme Java sur des plates-formes
diverses, pourvu qu'elles soient munies chacune de sa JVM. Cela permet à Java
de réaliser l'un des objectifs les plus ambitieux en informatique : "write
once - run anywhere", un programme une fois écrit peut être exploité sur
toutes les plates-formes. En outre Java fournit au programmeur des outils
commodes comme celui qui libère automatiquement la mémoire non
utilisée ("garbage collector"). Cette fonction faisait défaut en C
et C++, dans lesquels la gestion de la mémoire est un casse-tête pour les
programmeurs.
On doit ajouter à la liste de nombreux autres
langages : Eiffel, Objective C, Loops etc. Presque tous les langages
impératifs se sont dotés d'outils de programmation objet. Les
programmeurs compétents en programmation objet sont les plus demandés sur
le marché. Les langages de programmation objet sont
entourés d'outils de productivité pour le programmeur professionnel :
générateurs automatiques de code, bibliothèques de classes, environnement de développement
intégré, outils de test etc.
Faut-il désormais tout programmer
en langage objet ? pas nécessairement. Pour des applications simples, ou entre les mains d'un
programmeur rigoureux, la programmation impérative est efficace - et on peut faire beaucoup de
choses en utilisant simplement Excel, Word, PowerPoint et FrontPage ! Par
ailleurs, l'essentiel des applications exploitées dans les
entreprises a été programmé en Cobol ; elles fonctionnent correctement et il
faudra pendant des années encore assurer leur maintenance, ce qui assure une
longue vie à la programmation en Cobol.
|